Masked Lip-Sync Prediction by Audio-Visual
Contextual Exploitation in Transformers
3. The University of Sydney. 4. Monash University. 5. S-Lab, Nanyang Technological University.
Abstract
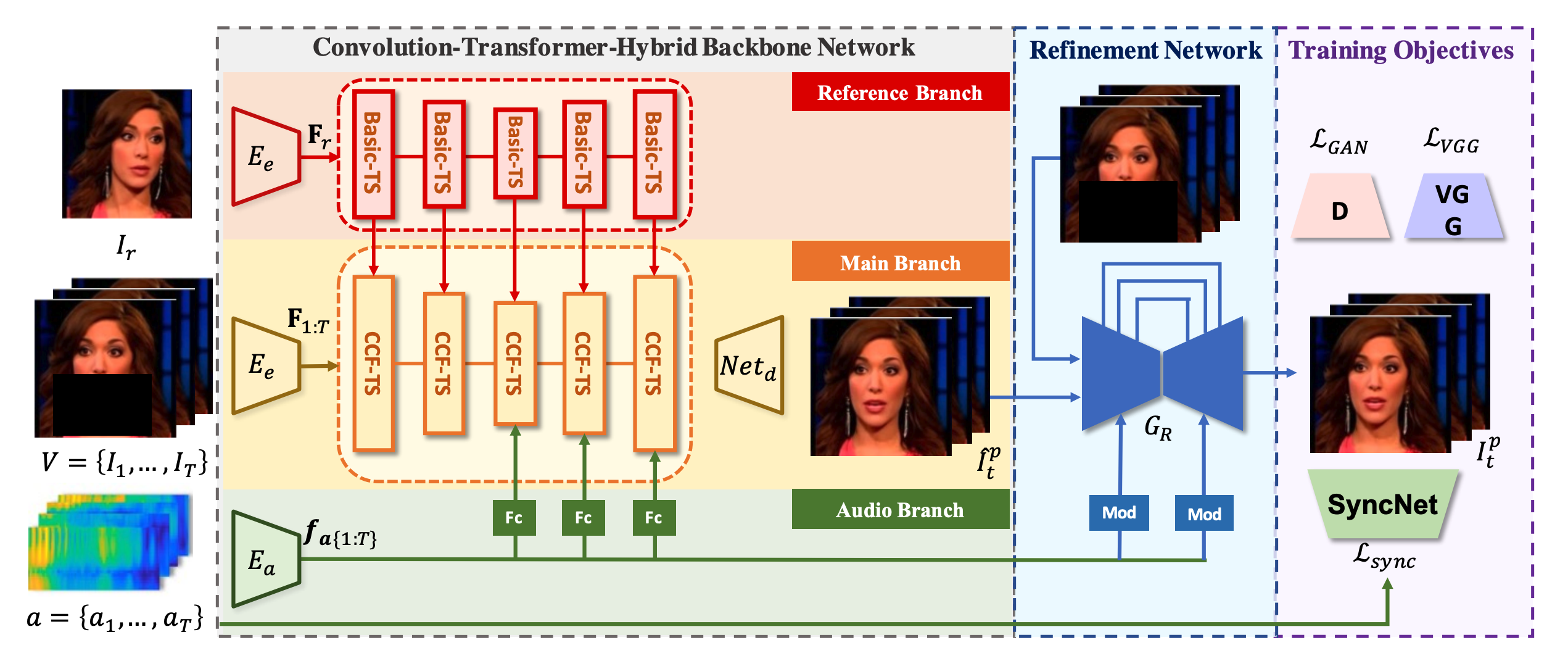
Previous studies have explored generating accurately lip-synced talking faces for arbitrary targets given audio conditions. However, most of them deform or generate the whole facial area, leading to non-realistic results. In this work, we delve into the formulation of altering only the mouth shapes of the target person. This requires masking a large percentage of the original image and seamlessly inpainting it with the aid of audio and reference frames. To this end, we propose the Audio-Visual Context-Aware Transformer (AV-CAT) framework, which produces accurate lip-sync with photo-realistic quality by predicting the masked mouth shapes. Our key insight is to exploit desired contextual information provided in audio and visual modalities thoroughly with delicately designed Transformers. Specifically, we propose a convolution-Transformer hybrid backbone and design an attention-based fusion strategy for filling the masked parts. It uniformly attends to the textural information on the unmasked regions and the reference frame. Then the semantic audio information is involved in enhancing the self-attention computation. Additionally, a refinement network with audio injection improves both image and lip-sync quality. Extensive experiments validate that our model can generate high-fidelity lip-synced results for arbitrary subjects.
Demo Video
Materials

Citation
@inproceedings{sun2022masked,
author = {Sun, Yasheng and Zhou, Hang and Wang, Kaisiyuan and Wu, Qianyi and Hong, Zhibin and Liu, Jingtuo and Ding, Errui and Wang, Jingdong and Liu, Ziwei and Hideki, Koike},
title = {Masked Lip-Sync Prediction by Audio-Visual Contextual Exploitation in Transformers},
year = {2022},
series = {SA '22 Conference Papers}
}
}