Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation
3. SenseTime Research 4. S-Lab, Nanyang Technological University
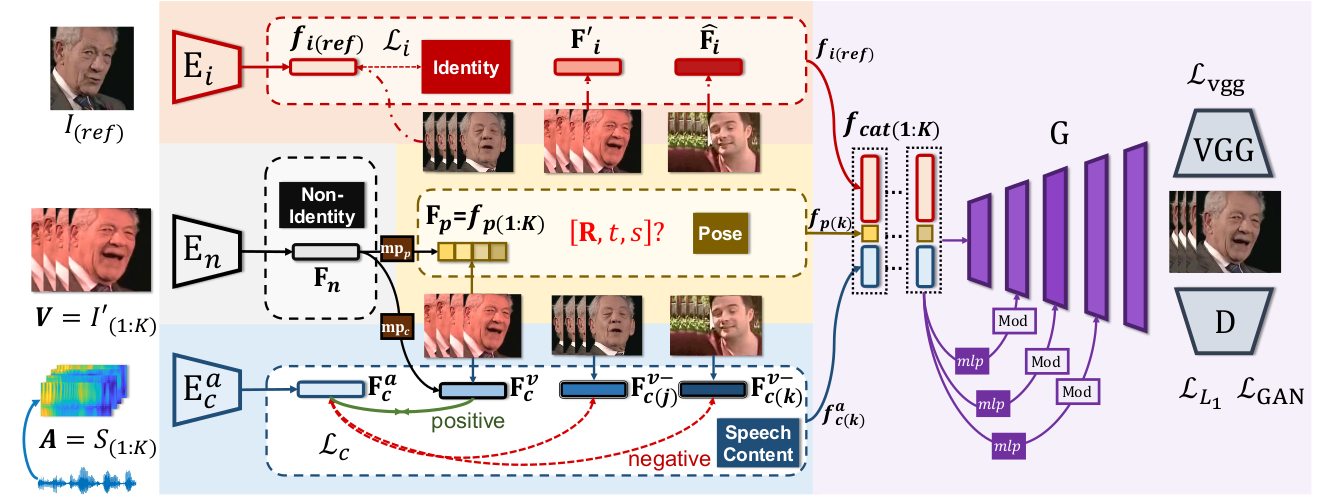
Abstract
While accurate lip synchronization has been achieved for arbitrary-subject audio-driven talking face generation, the problem of how to efficiently drive the head pose remains. Previous methods rely on pre-estimated structural information such as landmarks and 3D parameters, aiming to generate personalized rhythmic movements. However, inaccuracy of such estimated information under extreme conditions would lead to degradation problems. In this paper, we propose a clean yet effective framework to generate pose-controllable talking faces. We operate on non-aligned raw face images, using only a single photo as identity reference. The key is to modularize audio-visual representations by devising an implicit low-dimension pose code. Substantially, both speech content and head pose information lie in a joint non-identity embedding space. While speech content information can be defined by learning the intrinsic synchronization between audio-visual modalities, we identify that a pose code will be complementarily learned in a modulated convolution-based reconstruction framework.
Demo Video
Materials

Code and Models

Citation
@inproceedings{Zhou2021Pose,
title = {Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation},
author = {Zhou, Hang and Sun, Yasheng and Wu, Wayne and Loy, Chen Change and Wang, Xiaogang and Liu, Ziwei},
booktitle = {Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021}
}