Speech2Talking-Face: Inferring and Driving a Face with Synchronized Audio-Visual Representation
2. Multimedia Laboratory, The Chinese University of Hong Kong
3. S-Lab, Nanyang Technological University
Abstract
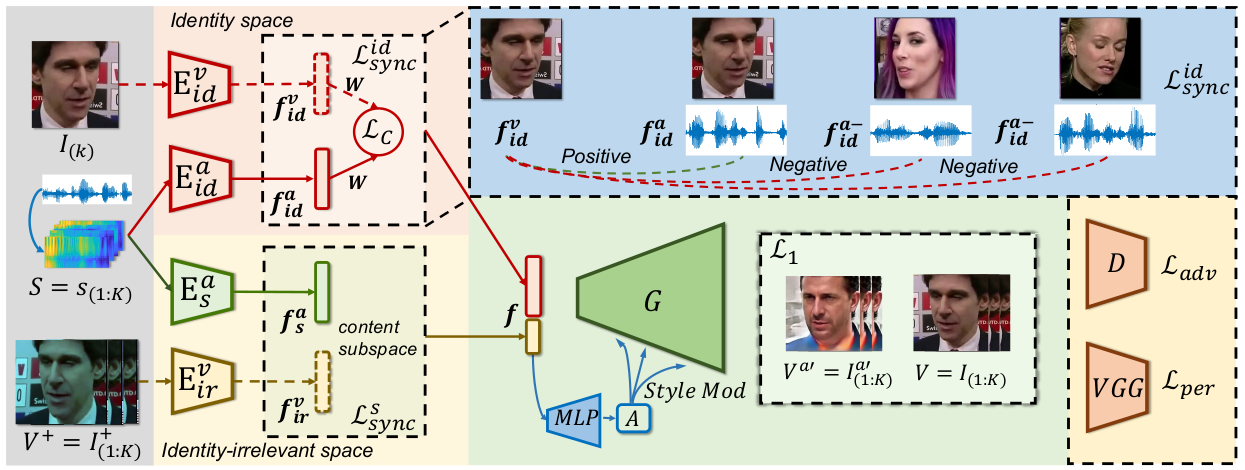
What can we picture solely from a clip of speech? Previous research has shown the possibility of directly inferring the appearance of a person's face by listening to a voice. However, within human speech lies not only the biometric identity signal but also the identity-irrelevant information such as the speech content. Our goal is to extract such information from a clip of speech. In particular, we aim at not only inferring the face of a person but also animating it. Our key insight is to synchronize audio and visual representations from two perspectives in a style-based generative framework. Specifically, contrastive learning is leveraged to map both the identity and speech content information within audios to visual representation spaces. Furthermore, the identity space is strengthened with class centroids. Through curriculum learning, the style-based generator is capable of automatically balancing the information from the two latent spaces. Extensive experiments show that our approach encourages better speech-identity correlation learning while generating vivid faces whose identities are consistent with given speech samples. Moreover, the same model enables these inferred faces to talk driven by the audios.
Demo Video
Materials

Code and Models

Citation
@inproceedings{sun2021speech,
title = {Speech2Talking-Face: Inferring and Driving a Face with Synchronized Audio-Visual Representation},
author = {Sun, Yasheng and Zhou, Hang and Liu, Ziwei and Koike, Hideki},
booktitle = {International Joint Conference on Artificial Intelligence (IJCAI) 2021},
year = {2021}
}