StyleSync: High-Fidelity Generalized and Personalized
Lip Sync in Style-based Generator
3. The University of Sydney, 4. S-Lab, Nanyang Technological University.
Abstract
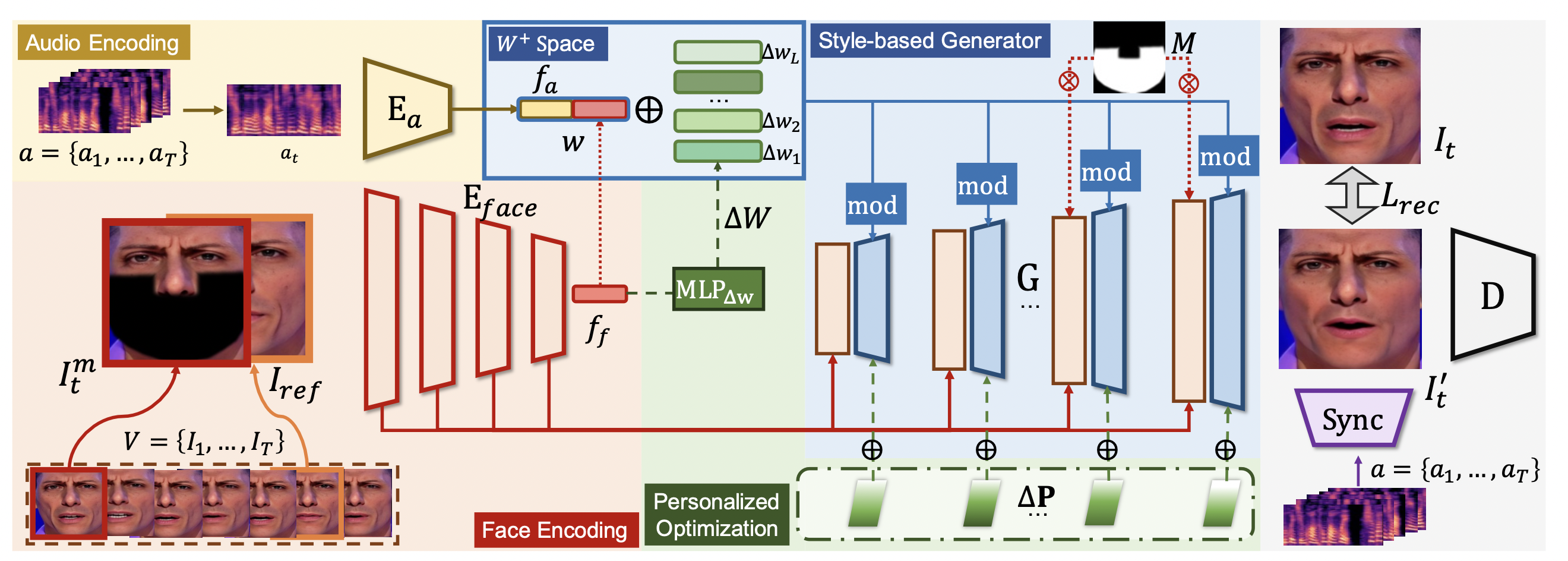
Despite recent advances in syncing lip movements with any audio waves, current methods still struggle to balance generation quality and the model's generalization ability. Previous studies either require long-term data for training or produce a similar movement pattern on all subjects with low quality. In this paper, we propose StyleSync, an effective framework that enables high-fidelity lip synchronization. We identify that a style-based generator would sufficiently enable such a charming property on both one-shot and few-shot scenarios. Specifically, we design a mask-guided spatial information encoding module that preserves the details of the given face. The mouth shapes are accurately modified by audio through modulated convolutions. Moreover, our design also enables personalized lip-sync by introducing style space and generator refinement on only limited frames. Thus the identity and talking style of a target person could be accurately preserved. Extensive experiments demonstrate the effectiveness of our method in producing high-fidelity results on a variety of scenes.
Demo Video
Materials

Code and Models

Citation
@inproceedings{guan2023stylesync,
title = {StyleSync: High-Fidelity Generalized and Personalized Lip Sync in Style-based Generator},
author = {Guan, Jiazhi and Zhang, Zhanwang and Zhou, Hang and HU, Tianshu and Wang, Kaisiyuan and He, Dongliang and Feng, Haocheng and Liu, Jingtuo and Ding, Errui and Liu, Ziwei and Wang, Jingdong},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2023}
}