Vision-Infused Deep Audio Inpainting
Abstract
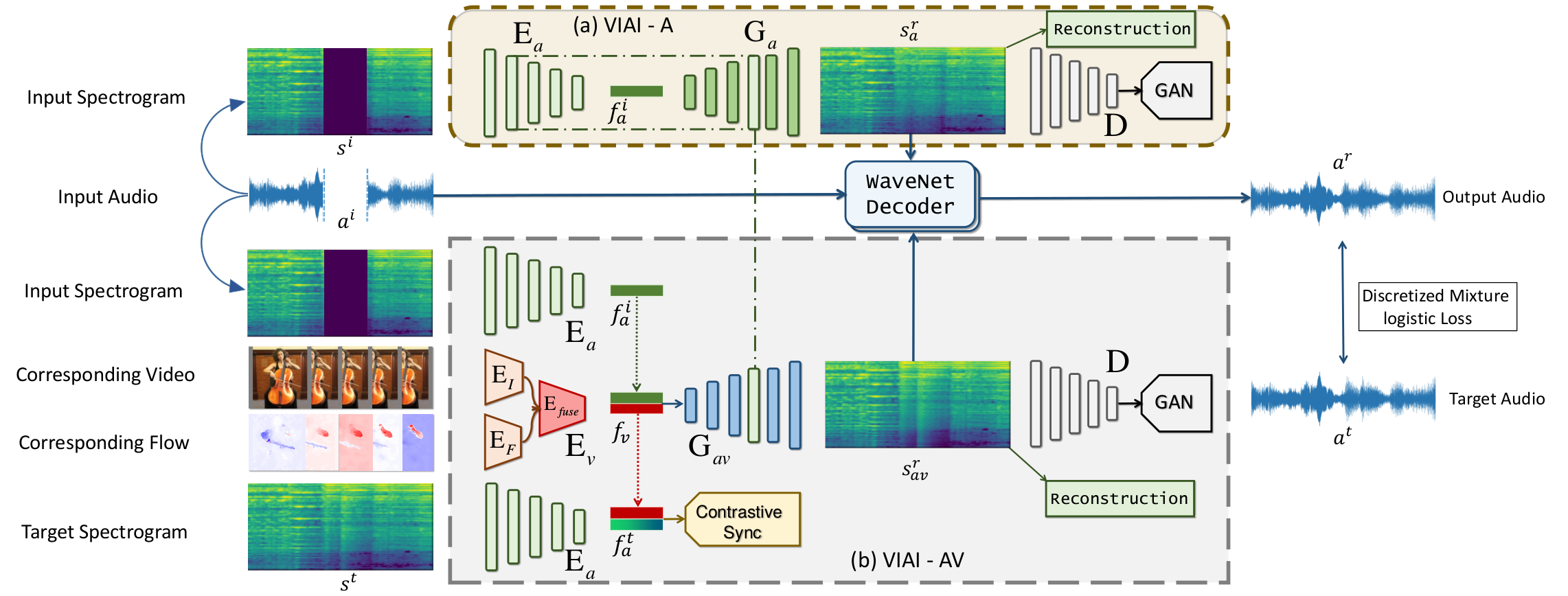
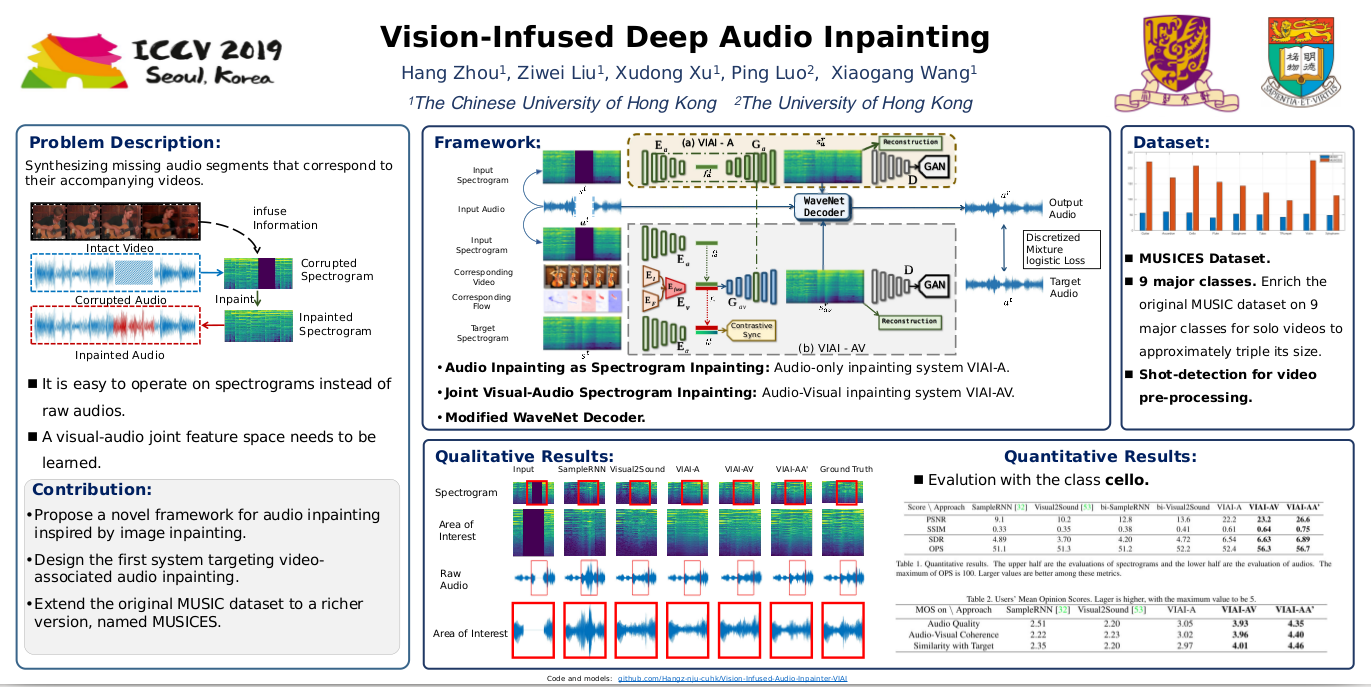
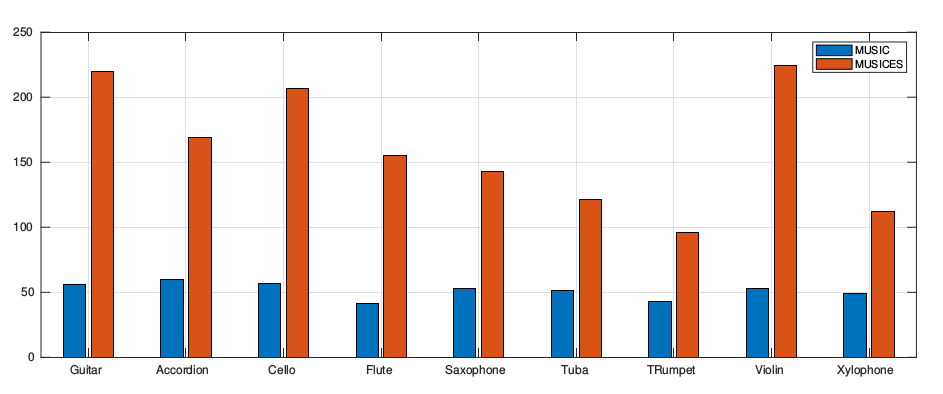
Multi-modality perception is essential to develop interactive intelligence. In this work, we consider a new task of visual information-infused audio inpainting, i.e. synthesizing missing audio segments that correspond to their accompanying videos. We identify two key aspects for a successful inpainter: (1) It is desirable to operate on spectrograms instead of raw audios. Recent advances in deep semantic image inpainting could be leveraged to go beyond the limitations of traditional audio inpainting. (2) To synthesize visually indicated audio, a visual-audio joint feature space needs to be learned with synchronization of audio and video. To facilitate a large-scale study, we collect a new multi-modality instrument-playing dataset called MUSIC-Extra-Solo (MUSICES) by enriching MUSIC dataset. Extensive experiments demonstrate that our framework is capable of inpainting realistic and varying audio segments with or without visual contexts. More importantly, our synthesized audio segments are coherent with their video counterparts, showing the effectiveness of our proposed Vision-Infused Audio Inpainter (VIAI).
Demo Video

Code, Models and Dataset

Citation
@InProceedings{Zhou_2019_ICCV,
author = {Zhou, Hang and Liu, Ziwei and Xu, Xudong and Luo, Ping and Wang, Xiaogang},
title = {Vision-Infused Deep Audio Inpainting},
booktitle = {The IEEE International Conference on Computer Vision (ICCV)},
month = {October},
year = {2019}
}
If you use the MUSICES dataset, please also cite:
@InProceedings{Zhao_2018_ECCV,
author = {Zhao, Hang and Gan, Chuang and Rouditchenko, Andrew and Vondrick, Carl and McDermott, Josh and Torralba, Antonio},
title = {The Sound of Pixels},
booktitle = {The European Conference on Computer Vision (ECCV)},
month = {September},
year = {2018}
}